
The Next 10 years of Cloud Native and Kubernetes — Finding ways to deal with Complexity
After ten years of Kubernetes and Cloud Native, the project landscape has grown to over 200 active projects governed by the CNCF. This reflects a remarkable success story, highlighting the innovative potential that Kubernetes and containers have ignited. Most of these projects build on each other, creating an interconnected ecosystem, with only a few functioning as standalone solutions. Beyond the CNCF, many Apache Foundation and other open source projects also integrate seamlessly into a cloud-native stack.

It is usually a good practice to take a bit of time every now and then to reassess the landscape and state to contribute towards developing adjustments based on it. With so many projects, a ton of obligations a platform engineering team has to comply; with new (and old) trends and technologies coming to the cloud native stack (AI, WASM, Bare Metal, etc.) there is consistently a feeling surfacing of juggling with a lot of complexity. Sorting all of this is difficult in itself so read this with a grain of salt and take it for what its worth.
Ecosystems as Trees and Puzzles
Kubernetes was built to orchestrate containers at scale, inspired by the needs of microservice and service-oriented architectures. Its methodology sparked the development of the cloud-native field and set the foundation for the CNCF. One of the primary accomplishments of the cloud-native community and pioneering container technology companies in the past ten years was to innovate and mature containers. The cloud-native scope was always larger than Containers and Kubernetes itself, envisioning hosting all kinds of technologies to power cloud-native stacks. Technologies serving our cloud needs are described by their ability to host services that dynamically respond to varying usage patterns, enabling business models made possible through open source and accessible to the entire industry. The cloud-native environment was always and is still gravitating to Kubernetes, the core of the ecosystem. This is not inherently an issue and more an observation. It depends on how you understand and describe an ecosystem; is the ecosystem understood like a tree with deep roots that are sprouting off in various directions to gain more ground, or is the ecosystem understood like a somewhat dynamic puzzle that can be arranged in different ways to provide its functionality. This could also be described as a platform- or a moduled-approach.

- With the tree model, you have a foundational base from which capabilities are developed and branched off. Developed capabilities rely on the interfaces of the trunk and complement its functionality. This approach has both strengths and weaknesses: it enables fast development but imposes limitations dictated by the trunk itself. In this model, Kubernetes acts as the trunk, providing a powerful base. Interfaces provided by CRDs, operators, sidecars patterns, cluster api or any of the many individual components itself allow other projects like KubeVirt, Linkerd, Crossplane (and so many more) to branch out to enable additional functionalities. These functionalities work only with the trunk or some version of it.
- The puzzle model is based on interoperability layers and aligns with the UNIX philosophy of "doing one thing and doing it right." A great example is the shell, where programs can be chained together using pipe operators to perform complex tasks. Each program serves a distinct purpose, but their modularity allows them to be combined, forming a cohesive system to address more complex needs collaboratively.
Two Ecosystem Interpretations: Kubernetes (Tree/ Trunk) and Nomad (Puzzle)
Comparing Kubernetes and HashiCorp Nomad illustrates how modularity is implemented differently and how this impacts component development. Both solve the problem of workload orchestration in distributed environments but differ in their architectural approaches. Kubernetes deployments vary based on the functionalities included in the cluster, with additional features integrated directly into the platform, altering its topology and introducing new notions to the system (this is a powerful mechanism). In contrast, Nomad’s deployment remains consistent, with capability enhancements like HashiCorp Vault or HashiCorp Consul added adjacent to it. With this Nomad simplifies setup with a single binary, running either as a server or client using nomad agent --server or nomad agent --client. The setup of Consul or Vault are along the lines of Nomad.
- Nomad follows the idea of a composable modular architecture, where individual components work together to enhance each other’s capabilities. As an example, Nomad has basic service discovery functionalities that can be enhanced with Consul (Service Mesh). Consul can also be used without Nomad to connect services. Both services can function independently but can be combined to deliver enhanced functionality (Interoperability).
- In Kubernetes, you find built-in service discovery functionalities such as Kubernetes Services and CoreDNS, which provide basic service discovery through ClusterIP addresses and DNS names. However, to enhance this functionality, the Kubernetes platform itself is extended rather than relying solely on external components. For example, you can deploy Linkerd, a lightweight service mesh that uses sidecar proxies to provide advanced capabilities such as observability, traffic management, and secure communication. Linkerd creates a dedicated namespace and registers a admission webhook in the Kubernetes control plane to automatically inject sidecar proxies into newly created Pods.

There are good reasons why Kubernetes is preferred over Nomad in the vast majority of cases (Kubernetes is favored over Nomad in most cases due to its robust community support, extensive feature set, expandability, and ecosystem, whereas Nomad's reliance on HashiCorp, combined with the company's recent open-source license changes, has raised trust concerns within the open-source community.). However, from what I can tell, without being a Nomad expert, Kubernetes may benefit from adopting some aspects of the UNIX philosophy, particularly in modularity and simplicity, to balance its inherent complexity with the need for flexibility.

Perhaps the tree model and puzzle model can also be thought together. Continue branching off Kubernetes at its core but improving its modularity to decompose complexity.
Kubernetes Complexity
Kubernetes is often perceived as complex, as described in the beginning, partly because of its extensible platform and the broad cloud native ecosystem surrounding it. While its modularity allows the platform to grow and adapt, it also adds layers of complexity. In managed service offerings like GKE, EKS or RKE, much of this complexity can be abstracted away, making Kubernetes easier to use. This is also one of many ways to deal with Kubernetes complexity. However, the underlying platform remains intricate.
From my perspective, Kubernetes' complexity can be sorted into three areas:
- The container and microservice mindset that influenced its design.
- The internal APIs and mechanisms for extending Kubernetes capabilities.
- The expansive scope of the cloud-native ecosystem that integrates with Kubernetes.
First Source of Complexity: Container & Microservice Mindset
Kubernetes was created for and around container technology. Containers are a form of workload virtualization based on the combination of several Linux kernel features (namespaces for isolation and control groups for resource limitation). Containers are a pragmatic virtualization approach that provides an easier and more performant way to manage applications, addressing some of the limitations of traditional VMs. This was the state of play in 2014 and the years since, when Docker introduced container technology to the wider industry.

VMs are costly, while containers are cheaper, which aligns well with the microservices and cloud paradigms where smaller components can be packaged, scaled individually, and restarted without interference. However, the ecosystem has since evolved, introducing additional runtime environments and formats to evaluate. These technologies complement each other; VMs are not inherently better or worse than containers — they are simply different technologies, as is the case with WASM, for example (BEAM VM or JVM (et al.) could also be put into this mix.).

Kubernetes is primarily about container orchestration rather than generalized workload orchestration. A less opinionated approach, like the one taken by Nomad—where all kinds of workloads are wrapped into tasks (akin to Pods in Kubernetes)—might represent an interesting development path. Containers are not fundamentally better than VMs, microVMs or WASM but complement them as a pragmatic lightweight and high-performance and well established and understood technology.
The container runtime architecture is relatively complex with a multiple pieces where engineers can hook in their own developments. Because of this containers are a more diluted interoperability layer which opens the door for additional complexity.

The architectural complexity of containers is absorbed and managed by Kubernetes. Like Linux, Kubernetes uses namespaces, but these do not inherently provide a consistent security layer. Instead, they offer conditional logical security isolation, which depends on proper configuration of additional measures such as network policies for network isolation and RBAC (Role-Based Access Control) for fine-grained access control. Without these additional safeguards, namespaces alone provide limited security functionality. This adds complexity in some ways since you need to validate that all levers are set to provide functionality. If you introduce this kind of uncertainty you always question things, “is it now actually secure”.
Kubernetes might evolve by adopting a less container-opinionated approach, and architecture mindset supporting diverse workload types beyond containers.
Second Source of Complexity: Extending Kubernetes via Internal APIs
One of the reasons why Kubernetes caught on lies within extendability and adaptability as described before. Kubernetes achieves this splitting up its core functionality into multiple components that work together. Each component has some interface that you can mock and build on top of.

One example that illustrates this is the scheduler framework that exposes a bunch of hooks to customize the scheduling behavior. Having this granular control allows advanced adjustments to tweak the platform to your specific needs. After all open source is a collaborative environment and if more people can make use of a technology it has the potential to gain more traction. Therefore extensibility and adaptability are important traits. That there are performance and complexity issues with the scheduler framework is right now not too important (performance because of largely sync processing and not async and some (debatable) irrelevant hooks that increase complexity).

One issue with internal interfaces are that once these interfaces are adapted by other projects and these projects are gaining traction too, the architecture is freezes. There are only so many options to change Kubernetes if you put on guard rails all around you. Shades of gray with interfaces increases the engineering challenges and the potential to “hack” the system in some ways to find a solution for your challenges.
Custom resource definitions and operators are probably the most common way to extend Kubernetes capabilities. Custom Resource Definitions (CRDs) and Operator Pattern have undeniable benefits and are core to some of the cloud native projects that emerged since then. However both have an aftertaste of expressing ambiguity. CRDs and Operators are a pragmatic way to just get things done.
Kubernetes could benefit from taking inspiration from distributions like K0s, which emphasize simplicity and fewer moving parts. For instance, components can be compiled together while maintaining flexibility — such as K0s does by swapping SQLite for etcd when needed (single node, multi nodes) — within a composable architecture.
Third Source of Complexity: The Broad Cloud Native Scope
In 2016, the Cloud Native reference architecture described the layers “workloads,” “orchestration & management,” “runtime,” “provisioning,” and “bare metal / cloud provider,” with the latter being out of scope. The reference architecture opens up a wide range. It's not just about workload orchestration. It's not just about containers. It's not about service discovery. It's about all of that and more—a lot of scope for one field.

With advancements in the bare metal space, such as IronCore or Harvester, you could argue that bare metal is now part of the cloud-native ecosystem. These tools bridge traditional infrastructure and cloud-native paradigms by incorporating features like provisioning and workload management directly on bare metal systems.
Kubernetes, etcd, SPIRE, Linkerd, Backstage, and Cloud Custodian all fall within the “orchestration & management” layer. These projects are highly diverse: some, like Linkerd, provide services such as secure communication and service mesh capabilities, while others, like Cloud Custodian, focus on governance, and yet others, like Kubernetes itself, handle coordination, scheduling, and orchestration.
Management, as a term in the reference architecture, may not be the best descriptor. Cluster services might be a better term, as it encompasses the variety of components included within this layer. Runtime fits better within the provisioning layer since provisioning focuses on setting up and updating the host environment to enable orchestration, and runtime is an integral part of that process.

What is out of scope for cloud native? AI seems to be a topic for cloud native too, as Kubernetes provides the platform needed to enable GPU support and orchestrate AI workload training. On the other hand, you could argue AI is a good example of something out of scope since it pertains to application development. Whether a workload performs machine learning or another task is not inherently of interest to cloud-native infrastructure. If we want to reduce complexity its difficult to be about everything and all.
Finding ways to deal with complexity (X, Y, Z)
There are a lot of ways to reduce complexity. Changing how Kubernetes and some other cloud native projects work and are setup architecturally may be an option down the road. Moving towards a more modular architecture, building towards interoperability, specs and APIs.

By setting up a cloud native stack there are options to off load complexity vertically (“Y”, layers), or horizontally (“X”, features) as well as cross functional (“Z”, narrowing down individual engineering burden).
X, Horizontal Complexity — Focus on functionality
A platform engineering team has an array of topics to integrate and think about. Thanks to the rich cloud native ecosystem most of these complexities of each individual component do not need to be understood in the lowest of details and can be deployed. Scoping the feature set of the platform based on individual requirements is good (and usually normal a normal process) reducing complexity.
A platform engineering team must consider a broad range of topics to integrate and manage. The cloud native ecosystem abstracts much of the complexity, enabling teams to deploy individual components without requiring an in-depth understanding of their inner workings. We do not need to reinvent how GitOps is done and can pick among multiple implementations. Reducing complexity through scoping of the platform’s feature set based on specific requirements is a common and effective practice in software engineering in general. This also applies to platform engineering.

Scoping features, usage of projects to abstract features / capabilities the cluster should fulfill. Against feature creep and towards a mindful lean architecture.
Y, Vertical Complexity — Focus on layers of interoperability
The previously discussed reference architecture puts more or less everything in the cloud-native scope. Beyond reducing the features a platform needs to offer, a similar approach can be applied to the architectural layers themselves. If systems are built on public clouds, many complexities—such as setting up an Ingress, updating Kubernetes, and patching Linux—are handled automatically.

- Self-Service Platform: Empowering developers to autonomously manage the distribution of their applications. The platform engineering team should not need to deal with application-specific details, as these can be highly complex themselves. Structuring an application distribution requires knowledge about the applications, which introduces transitive complexity if platform engineers take on this responsibility.
- Provisioning Public cloud providers or projects like Harvester or Gardener can minimize tasks like OS installation and cluster connectivity through VPNs or VPCs. Similarly, horizontal complexity can be minimized by using specialized OSs such as Talos Linux or Elemental.
Reducing the configuration and engineering surface by building on abstractions helps offload responsibilities to layers of abstraction, moving away from managing everything.
Z, Engineering Complexity — Narrowing down and Focusing on areas of responsibility
After defining the framework through X and Y, the question remains: who should handle the remaining complexity, and can this workload be further reduced?
- What responsibilities does the platform engineering team take on?
- How can the platform engineering team work more efficiently and with greater focus?
Balancing Complexity for Platform Engineers
Platform engineers often face a wide range of topics to manage, and their ability to handle this complexity depends on several factors. The key is determining how many parameters they need to manage, how much detail is required, and how much responsibility they carry. If an engineer is responsible for only a subset of parameters in a complex system, the workload may be manageable. However, as their responsibilities increase—requiring them to lead and balance multiple parameters—the complexity becomes more difficult to handle.
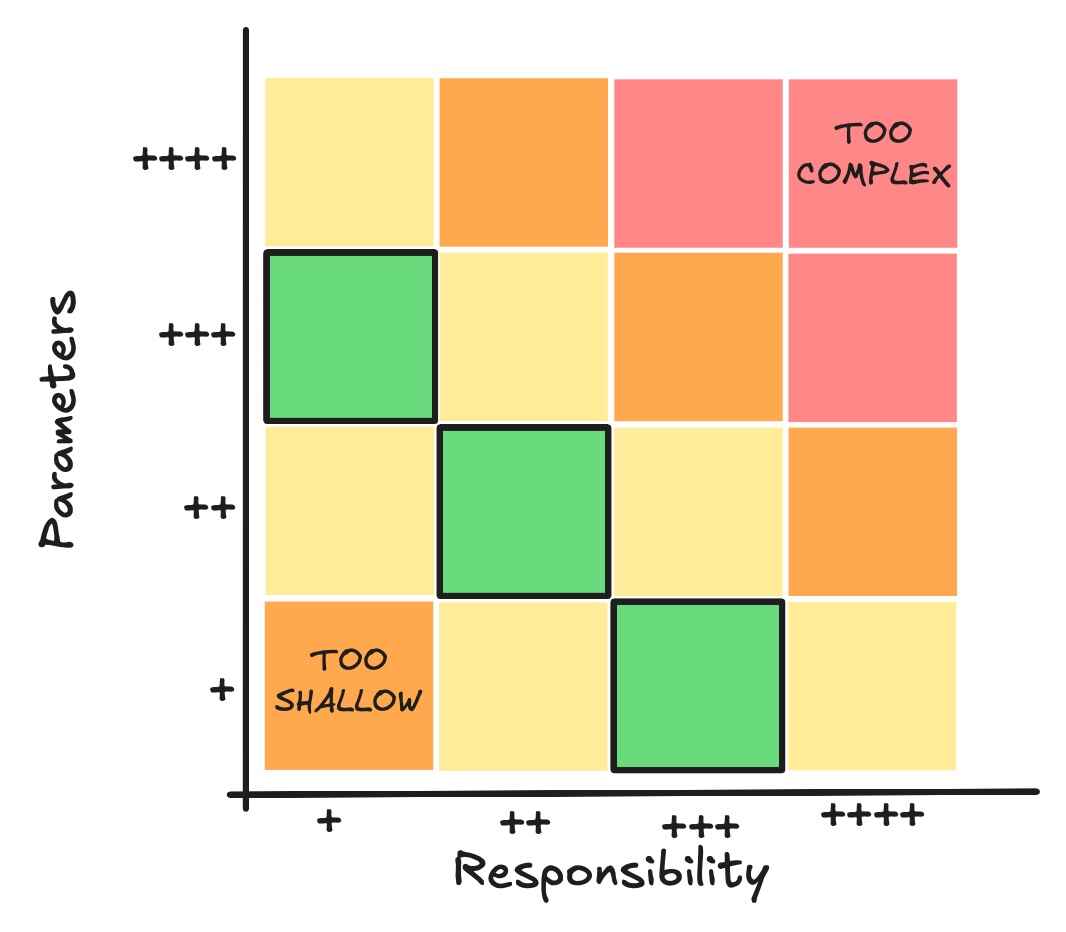
Cloud Infrastructure: A Shared Responsibility
The adoption of cloud-native technologies cannot be limited to the platform engineering or infrastructure team alone. Building and managing cloud infrastructure is inherently a shared responsibility involving multiple teams.
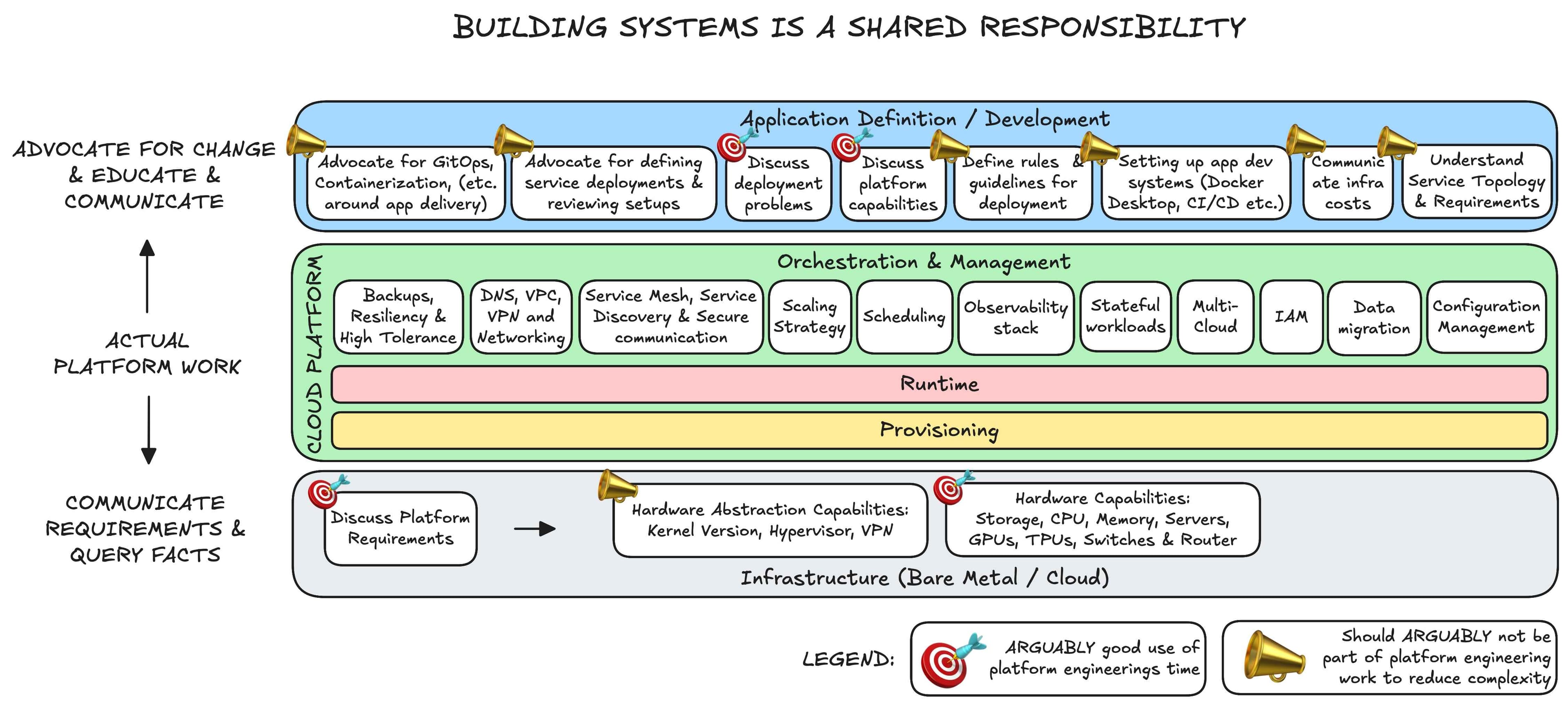
The diagram above highlights the topics a platform engineering team often deals with. Working with Kubernetes is already complex, and when advocacy, cross-team communication, and engineering tasks are added, the scope of work expands even further. Simplifying Kubernetes or related systems could make tasks like change management more manageable.
Ultimately, managing complexity depends on the engineer's ability to assess how many topics and parameters they can handle, how much responsibility they are willing to take on, and how well they can balance these demands within their role.
Summary
The cloud native ecosystem built around Kubernetes provides a solid foundation for creating cloud environments. The notion of this text is to build towards the idea of evolving Kubernetes beyond its container-centric origins, positioning it as a more flexible workload orchestrator by transitioning towards a Cloud Native Platform mindset that’s build on interoperability. Integrating a module approach (puzzle) with the platform approach (tree).